ChatGPT & Co. und Schule
Allgemeines
Was tun?
Weiteres
Vertiefendes
Weiterführendes
Unser Material
Unsere Kurse
Webtechnisches
Datenschutzaspekte bei schulischer GMLS-Nutzung
Worum geht es?
Auch bei ChatGPT & Co. stellt sich das übliche schulische Datenschutzdilemma: Aktuelle generative Maschine-Learning-Systeme lassen sich aufgrund der notwendigen Rechenkapazitäten derzeit meist noch nicht wirklich auf dem eigenen Rechner betreiben sondern erfordern eine Datenverarbeitung auf externen Servern. Damit stellt sich das übliche Datenschutzdilemma für Schulen: Ist es zulässig, dass schützenswerte Daten von Lehrkräften und meist minderjährigen Schüler:innen auf auf fremden Servern verarbeitet werden? Soll umgekehrt komplett auf die Nutzung solcher Dienste verzichtet werden, wenn dies nicht datenschutzkompatibel möglich ist?Aktuelle Nutzungsmodi von GMLS-Systemen
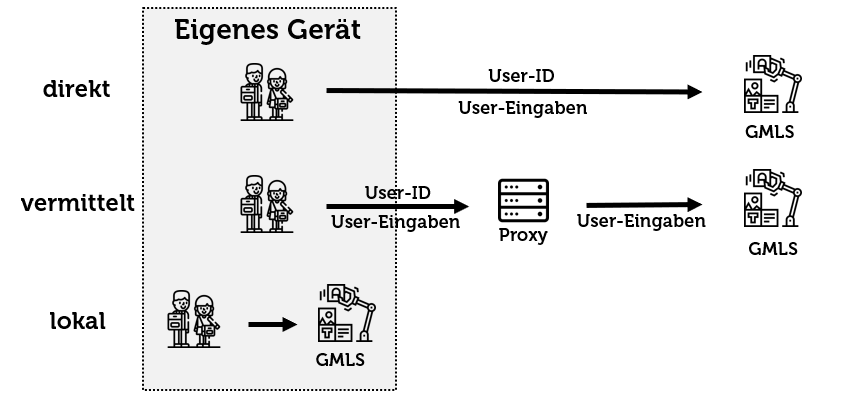
- direkt: Nutzende greifen direkt auf ein generatives Machine-Learning-System zurück, das sich auf einem externen Server befindet. Da solche Dienste meist mit User-Konten arbeiten, gelangen damit somit eine eindeutige User-ID (z.B. E-Mail-Adresse) und alle User-Eingaben zum GMLS-Anbieter.
- vermittelt: Sowohl aus didaktischen, administrativen, finanziellen und datenschutztechnischen Überlegungen haben sich zahlreiche Dienste etabliert, welche als Proxy / Relaisstation agieren, indem sie die Anfragen von Nutzenden entgegennehmen und entweder anonym oder pseudonym an ein externes GMLS weiterleiten. Dadurch gelangen zwar die ursprüngliche User-ID nicht mehr zum GMLS-Provider, sehr wohl aber weiterhin die Eingaben von Nutzenden.
- lokal: Während es Ende 2022 bei der Veröffentlichung von ChatGPT noch undenkbar schien, solch leistungsfähige GMLS auf lokalen Computern laufen zu lassen, haben die letzten anderthalb Jahre eine erstaunlich Entwicklung hervorgebracht, so dass heute auf leistungsfähigen lokalen Computern bereits generative Machine-Learning-Systeme verfügbar sind, die beinahe an die ursprüngliche Leistungsfähigkeit der ersten veröffentlichten ChatGPT-Version heranreichen. Da aber generative Machine-Learning-Systeme insgesamt an Leistungsfähigkeit zugelegt haben, sind servergestützte Systeme weiterhin deutlich leistungsfähiger als lokal installierte Systeme.
Solange generative Machine-Learning-Syteme nicht lokal betrieben werden, verlassen Daten den eigenen Rechner und es stellt sich ein Vertrauens- / Datenschutzproblem: wer hat Zugriff auf diese Daten, was darf er/sie damit gesetzlich machen und inwiefern darf darauf vertraut werden, dass sich entsprechende Stellen auch an die geltenden Gesetze halten?
Aus rechtlicher Sicht ist dabei relevant, wo die entsprechenden Server stehen und welchem Datenschutzgesetz sie in der Folge unterstehen.
In Realität sind die Datenflüsse komplexer als oben konzeptionell beschrieben. Hier ein Diagramm der Datenflüsse des Dienstes fiete.ai vom April 2024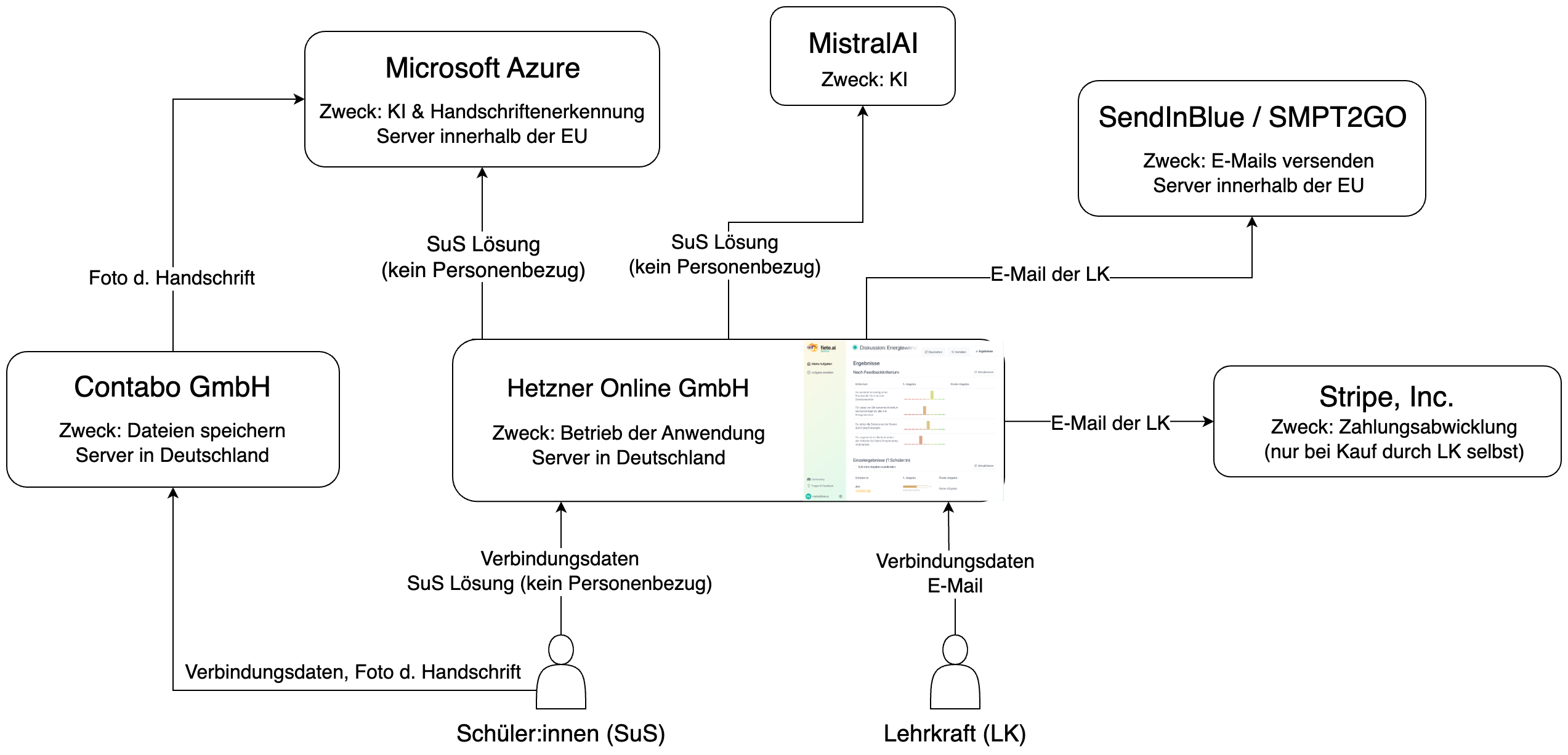
Quelle: fiete.ai
Entkoppelnde Zwischenlayer lösen das Problem nur teilweise
Aus didaktischen, administrativen, finanziellen und datenschutztechnischen Überlegungen sind bereits mehrere Dienste für Schulen aufgebaut worden, bei denen die Schülerinnen und Schüler kein persönliches Konto bei einem GMLS wie ChatGPT erstellen müssen, sondern ein zwischengelagerter Dienst die Anmeldung pseudonymisiert. Dies mag aus juristischer Sicht den Anforderungen des Datenschutzes genügen, löst das Problem aber nicht vollständig: Selbst wenn jemand keine Identifikationsmerkmale zur Anmeldung bei einem GMLS angibt, können die eingegebenen Daten bei der Nutzung eines GMLS aus Sicht des Datenschutzes besonders schützenswert sein (persönliche Erlebnisse, Leistungsbeurteilungen, psychologische Gutachten) und/oder Merkmale enthalten, die eine Identifikation der eingebenden Person erlauben. Diese Daten gelangen jedoch trotz Zwischenlayer weiterhin zum Anbieter des generativen Machine-Learning-Systems.
Schulisches Datenschutz-Dilemma: Zeitgemäss oder datenschutzkonform?
Auch bei generativen Machine-Learning-Systemen ergibt sich somit das übliche Datenschutzdilemma von Schulen: Werden die Datenschutzvorgaben für Schulen vollumfänglich beachtet, ist juristisch betrachtet derzeit oft keinerlei Nutzung von generativen Machine-Learning-Systemen in der Schule zulässig. Damit wird jedoch verhindert, dass der Umgang mit entsprechenden Werkzeugen ausprobiert, geübt und im Anschluss aufgrund praktischer Erfahrungen reflektiert werden kann - wohlwissend, dass gewisse Schüler:innen ausserhalb der Schule solche Werkzeuge sehr wohl nutzen. (Dieses Problem ist bereits älter, siehe z.B. hier eine Beschreibung des Dilemmas von 2013 bei der Nutzung von Cloud-Diensten)-Kontakt

 In: Brägger, Gerold & Rolff, Hans-Günter: Handbuch Lernen mit digitalen Medien (3. Auflage). Beltz Verlag. https://zenodo.org/records/15042499
In: Brägger, Gerold & Rolff, Hans-Günter: Handbuch Lernen mit digitalen Medien (3. Auflage). Beltz Verlag. https://zenodo.org/records/15042499